Chapter 7 Statistical Inference

Learning outcomes
-
Write
Rcode to fit a linear regression model, and interpret estimated coefficients of these models. For example: - no explanatory variable (a null model)
- a single continuous explanatory variable
- a single categorical explanatory variable (using dummy variables)
- a continuous and a categorical factor explanatory variable
- an interaction term in the explanatory variables
- Explain why you may want to include interaction terms in a model
-
Describe the differences between the operators
:and*in anRmodel-fitting formula - Demonstrate how to make point predictions from linear regression models. For example models with:
- a single continuous explanatory variable
- a continuous and a categorical factor explanatory variable
- an interaction term in the explanatory variables
-
Understand how to undertake model selection using the
anova()andAIC()functions in R and interpret the output -
Compute confidence intervals in
Rto estimate a population parameter, and interpret their meaning
7.1 Linear Regression
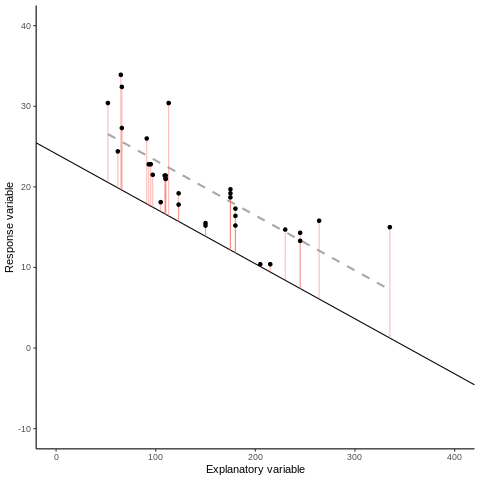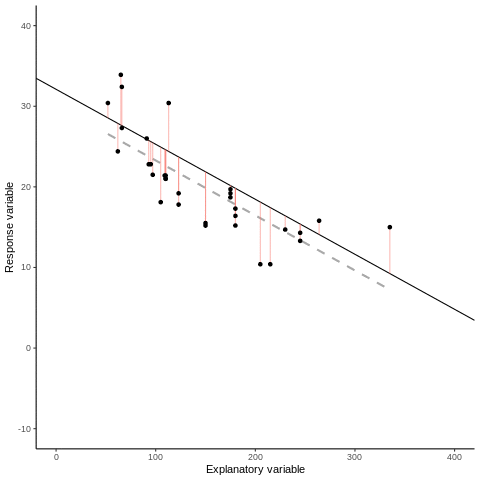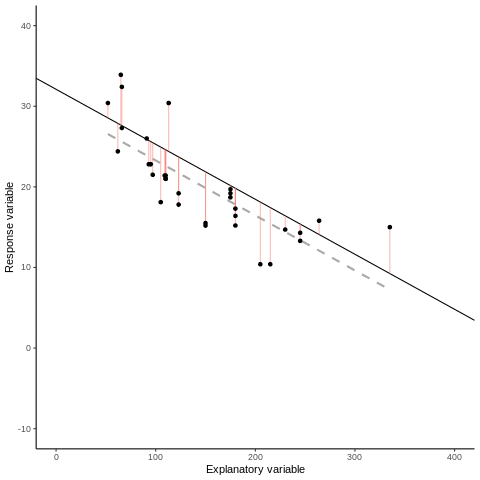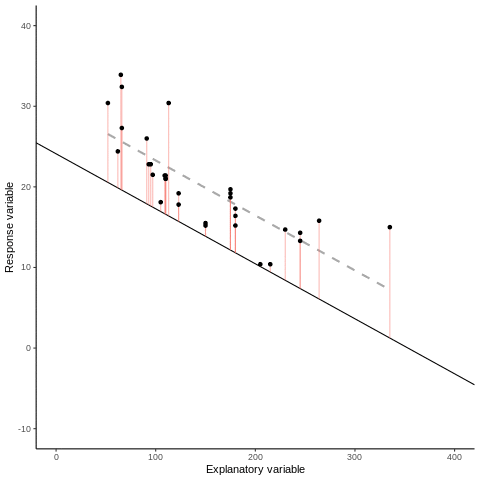
7.1.1 Some mathematical notation
Let’s consider a linear regression with a single explanatory variable. This is what the model looks like:
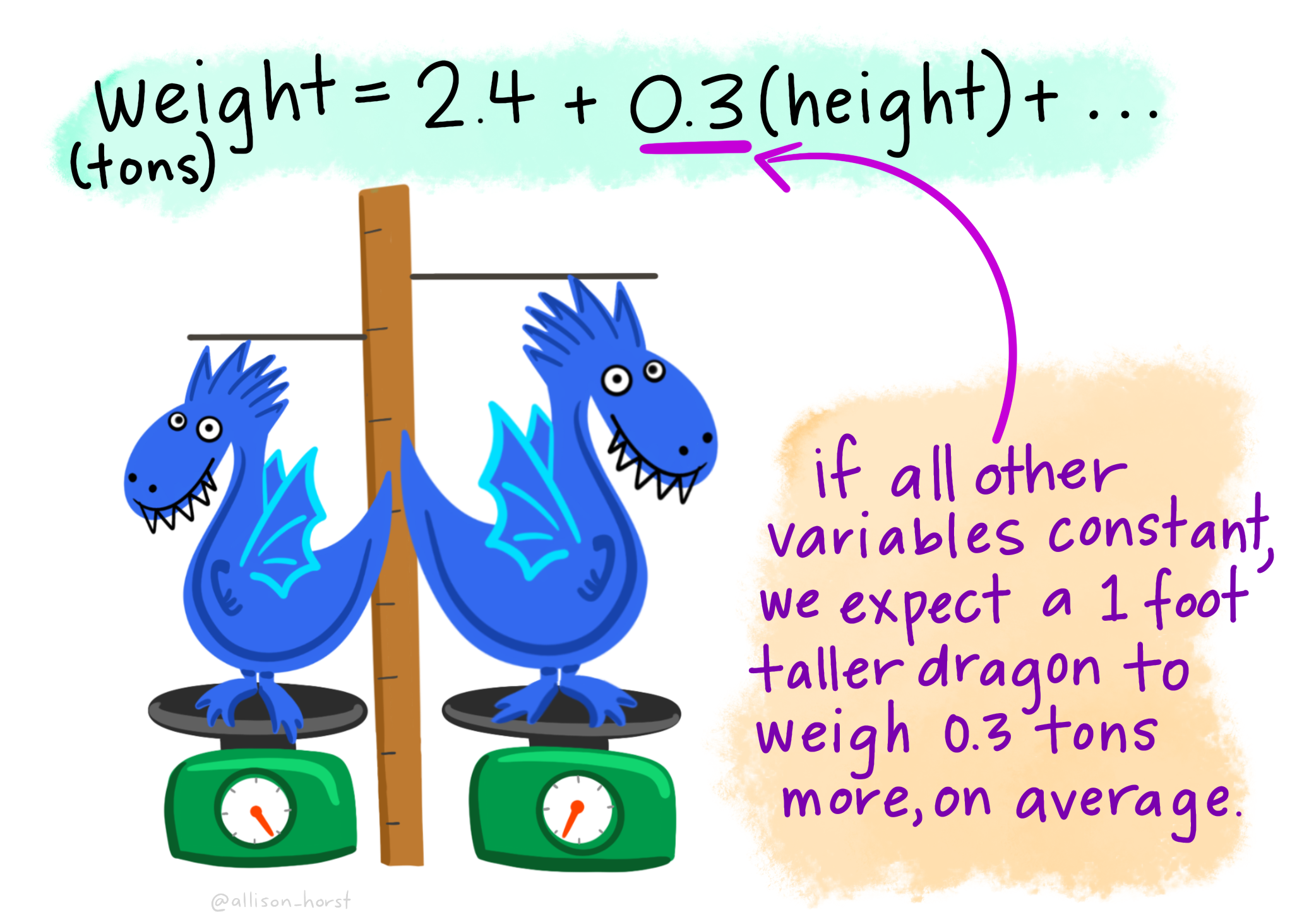
\[Y_i = \alpha + \beta_1x_i + \epsilon_i\] where
\[\epsilon_i \sim \text{Normal}(0,\sigma^2).\]
Here for observation \(i\)
- \(Y_i\) is the value of the response
- \(x_i\) is the value of the explanatory variable
- \(\epsilon_i\) is the error term: the difference between \(Y_i\) and its expected value
- \(\alpha\) is the intercept term (a parameter to be estimated), and
- \(\beta_1\) is the slope: coefficient of the explanatory variable (a parameter to be estimated)
Note: you may also see the intercept term \(\alpha\) written as \(\beta_0\)
Does this remind you of anything?

7.1.2 Modelling Bill Depth
In the following statistical inference sections, we will be working with our palmerpenguins data set, where we are interested in examining a few different linear regression models with a different numbers of explanatory variables that may help us explain the variation in bill depth bill_depth_mm, our response variable. We will start with the simplest model, with no explanatory variables, and then add in more explanatory variables (both categorical and continuous) and alter the way they interact with each other in the model, while seeing how to use this sample data to draw inferences about the underlying population.

Let’s take a look at the bill depth data in a histogram (it’s always nice to have a visual!).
ggplot(data = penguins_nafree, aes(x = bill_depth_mm)) +
geom_histogram() + theme_classic() +
xlab("Bill depth (mm)")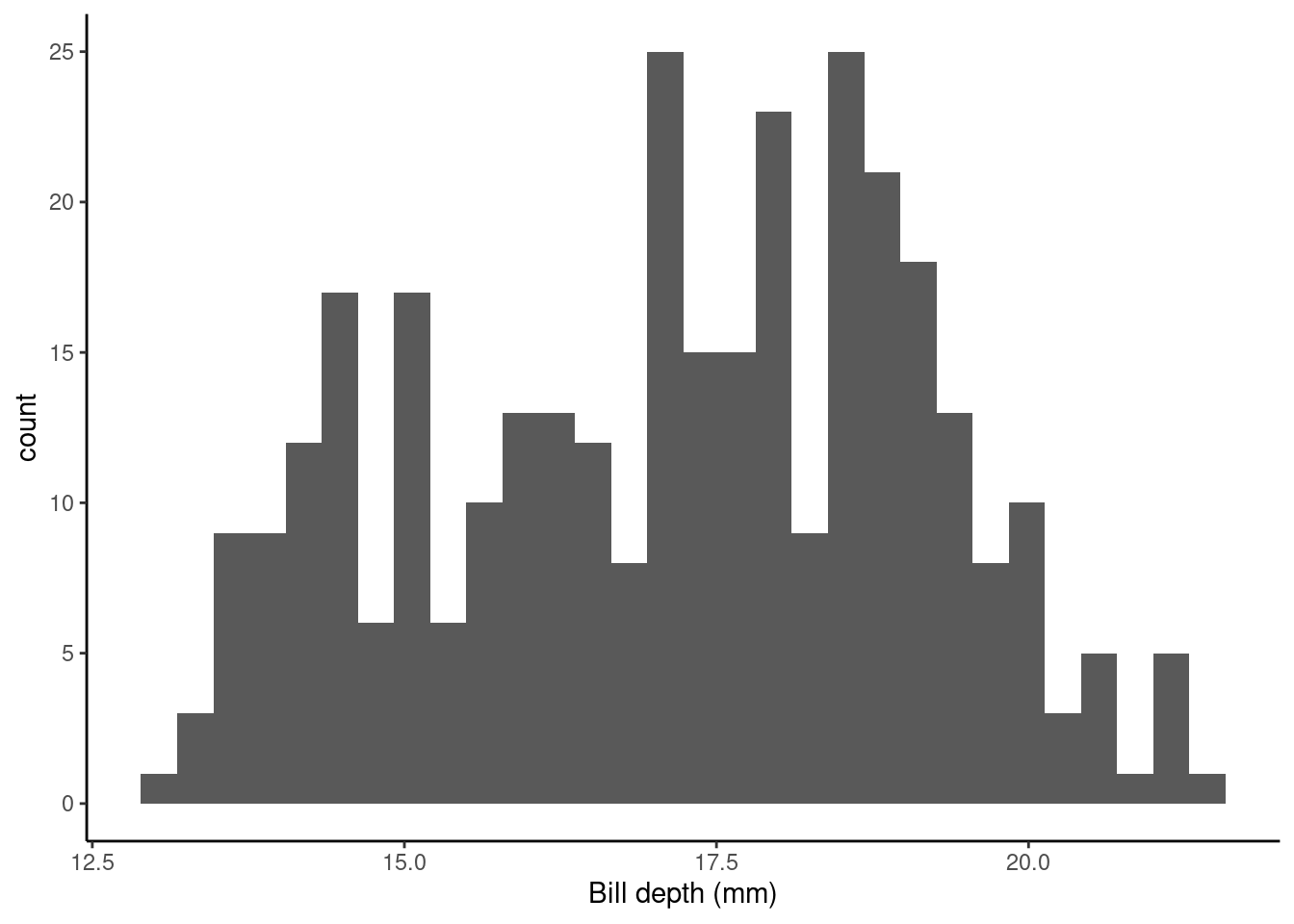
7.1.3 Intercept only (null) model
First off let’s fit a null (intercept only, no slope) model. This in old money would be called a one sample t-test.
Model formula
The null model formula is: \[Y_i = \alpha + \epsilon_i.\]
Here for observation \(i\), \(Y_i\) is the value of the response (bill_depth_mm) and \(\alpha\) is a parameter to be estimated (typically called the intercept).
The R code for this model specifies a 1 to represent a constant, as we have no explanatory variables in this model and there is no slope to estimate.
The hypotheses being tested are \(H_0:\mu_{\text{bill_depth_mm}} = 0\) vs. \(H_1:\mu_{\text{bill_depth_mm}} \neq 0\)
summary(slm_null)$coef
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 17.16486 0.1079134 159.0614 1.965076e-315So, what are the values/regression coefficients from the lm() output above?
Estimateof the(Intercept)= 17.1648649, tells us the (estimated) average value of the response (in this example, it is the estimate of the population mean (\(\mu\)) ofbill_depth_mm), which we can show using the code below:
penguins_nafree %>% summarise(average_bill_depth = mean(bill_depth_mm))
## # A tibble: 1 × 1
## average_bill_depth
## <dbl>
## 1 17.2The SEM (
Std. Error) = 0.1079134.The t-statistic is given by
t value=Estimate/Std. Error= 159.0614207The p-value is given by
Pr (>|t|)= 1.965076e-315
So the probability of observing a t-statistic as least as extreme given under the null hypothesis (average bill depth = 0) given our data is 1.965076e-315, pretty strong evidence against the null hypothesis I’d say! I hope this makes sense biologically as we would not expect the average bill depth of a penguin to be 0!
7.1.4 Single continuous explanatory variable
Does bill_length_mm help explain some of the variation in bill_depth_mm?
Model formula
The formula for this model is \[Y_i = \alpha + \beta_1x_i + \epsilon_i\] where for observation \(i\) \(Y_i\) is the value of the response (bill_depth_mm) and \(x_i\) is the value of the explanatory variable (bill_length_mm); \(\alpha\) and \(\beta_1\) are population parameters to be estimated using our sample data. We could also write this model as
\[ \begin{aligned} \operatorname{bill\_depth\_mm} &= \alpha + \beta_{1}(\operatorname{bill\_length\_mm}) + \epsilon \end{aligned} \]
Fitted model
We can output our estimated population parameters (\(\alpha\) and \(\beta_1\)) using
slm <- lm(bill_depth_mm ~ bill_length_mm, data = penguins_nafree)
summary(slm)$coef
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 20.78664867 0.85417308 24.335406 1.026904e-75
## bill_length_mm -0.08232675 0.01926835 -4.272642 2.528290e-05The Estimate of the (Intercept) (\(\alpha\) in the model) gives us the estimated average bill depth (mm) given the estimated relationship between bill length (mm) and bill depth (mm).
The Estimate of bill_length_mm (\(\beta_1\) in the model) is the slope associated with bill length (mm). Here for every 1mm increase in bill length we estimated a 0.082 mm decrease (or a -0.082 mm increase) in bill depth.
The plot below shows this relationship visually:
## calculate predicted values
penguins_nafree$pred_vals <- predict(slm)
## plot
ggplot(data = penguins_nafree, aes(x = bill_length_mm, y = bill_depth_mm)) +
geom_point() + ylab("Bill depth (mm)") +
xlab("Bill length (mm)") + theme_classic() +
geom_line(aes(y = pred_vals))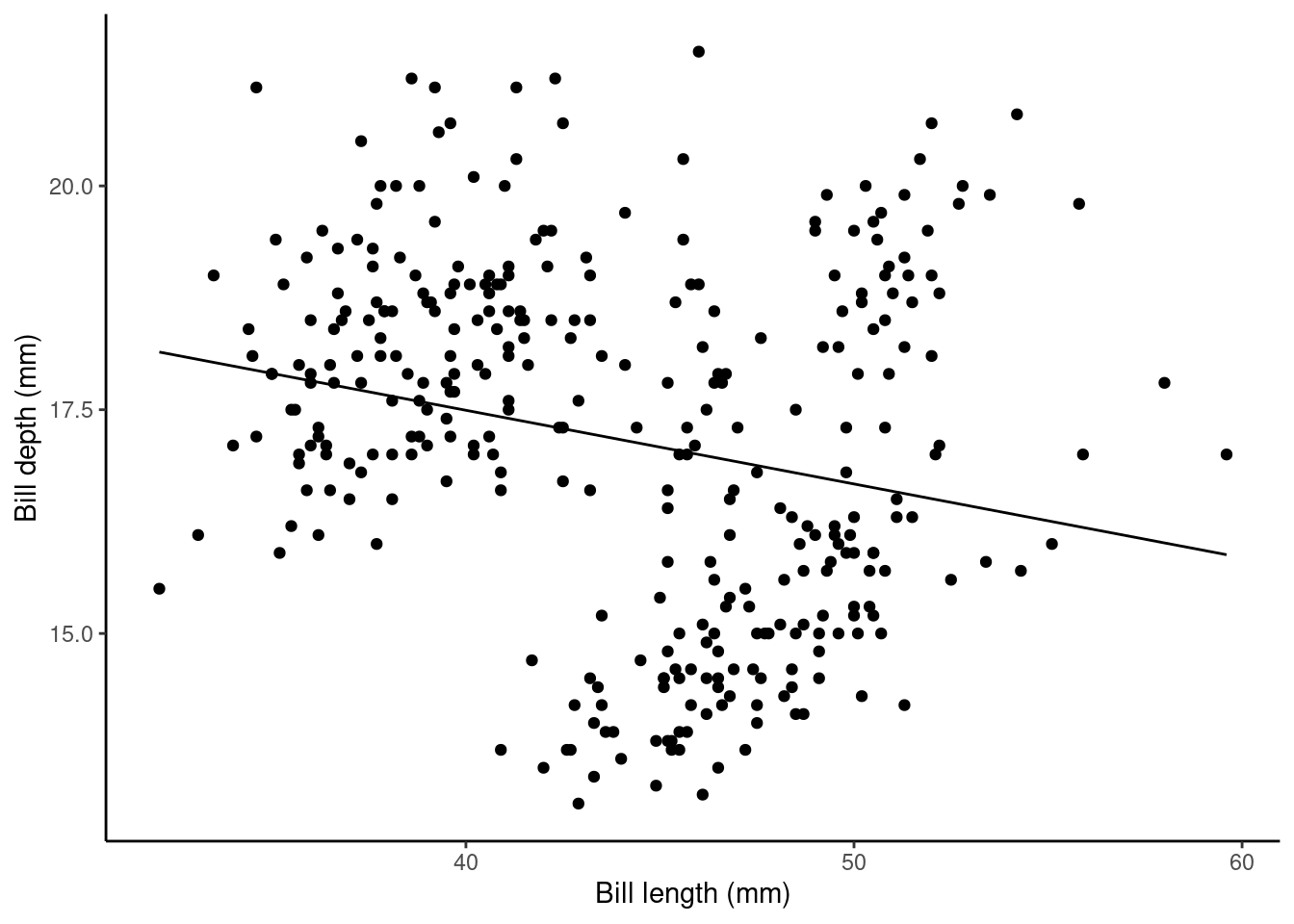
7.1.5 Single categorical explanatory variable
Let’s forget about bill_length_mm as an explanatory variable for a minute… Instead, let’s see if species can help explain some of the variation in bill_depth_mm. Here is a visualisation of this data:
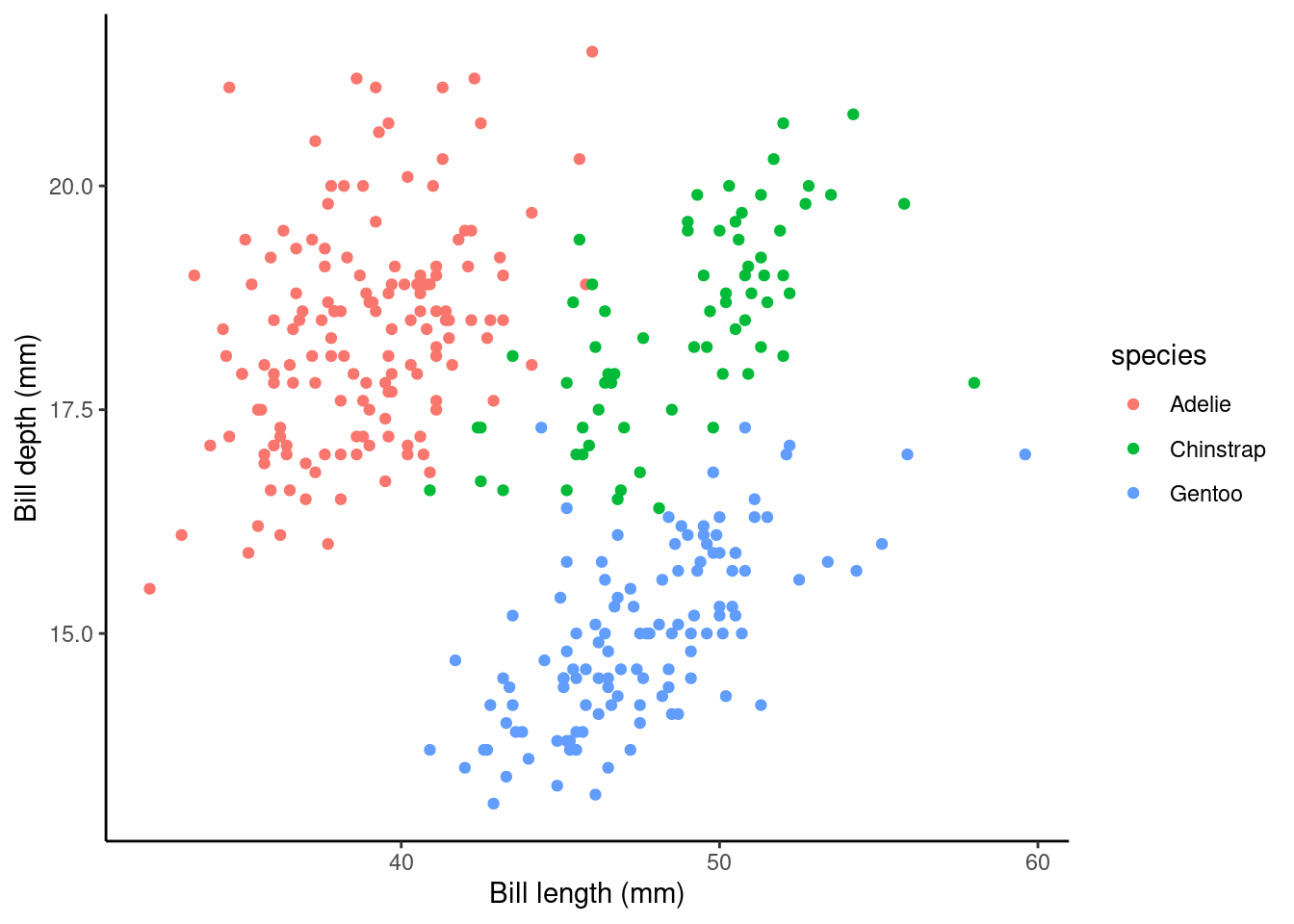
species is a categorical variable with three levels/groups: Adelie, Chinstrap and Gentoo. When we have categorical explanatory variables (e.g., species) we have to use dummy variables to estimate population parameters in our linear regression model. Why? Well, let’s consider what the y-intercept might be when our explanatory variable can never equal 0; our only options here are Adelie, Chinstrap and Gentoo.
What is a dummy variable?
It is a variable created to assign numerical value to levels of categorical variables. This is necessary with most categorical variables because an individual usually cannot be in more than one group/level (e.g., a Chinstrap penguin cannot be a Gentoo penguin too!). So the dummy variable coding works by representing one category of the explanatory variable and is coded with 1 if the case falls in that category and with 0 if not.
Here’s an example dummy variable table for species in the palmerpenguin data set:

Here the Adelie group/level is the baseline and as such will act as the y-intercept in our regression model (R does this alphabetically by default. To change this, we can use the mutate function. See section 6.1.4.2 in Hypothesis testing and introduction to linear regression for more details) so we assign a 0 to speciesChinstrap and a 0 to speciesGentoo to see what the response is for Adelie penguins (Intercept). This is shown in the top line row of the table above.
Model formula
The formula for this model is \[Y_i = \alpha + \beta_1x_{i,1} + \beta_2x_{i,2} + ... + \beta_kx_{i,k} + \epsilon_i\]
where for observation \(i\)
- \(Y_i\) is the value of the response (
bill_depth_mm) - \(x_{i,k}\) is the value of the explanatory variable (
bill_length_mm), where \(k\) is the number of levels of the explanatory variable - 1, because one level is the intercept term - \(\epsilon_i\) is the error term: the difference between \(Y_i\) and its expected value
- \(\alpha\), \(\beta_1\), \(\beta_2\), up to \(\beta_k\) are all parameters to be estimated using our sample data. We could also write this model as
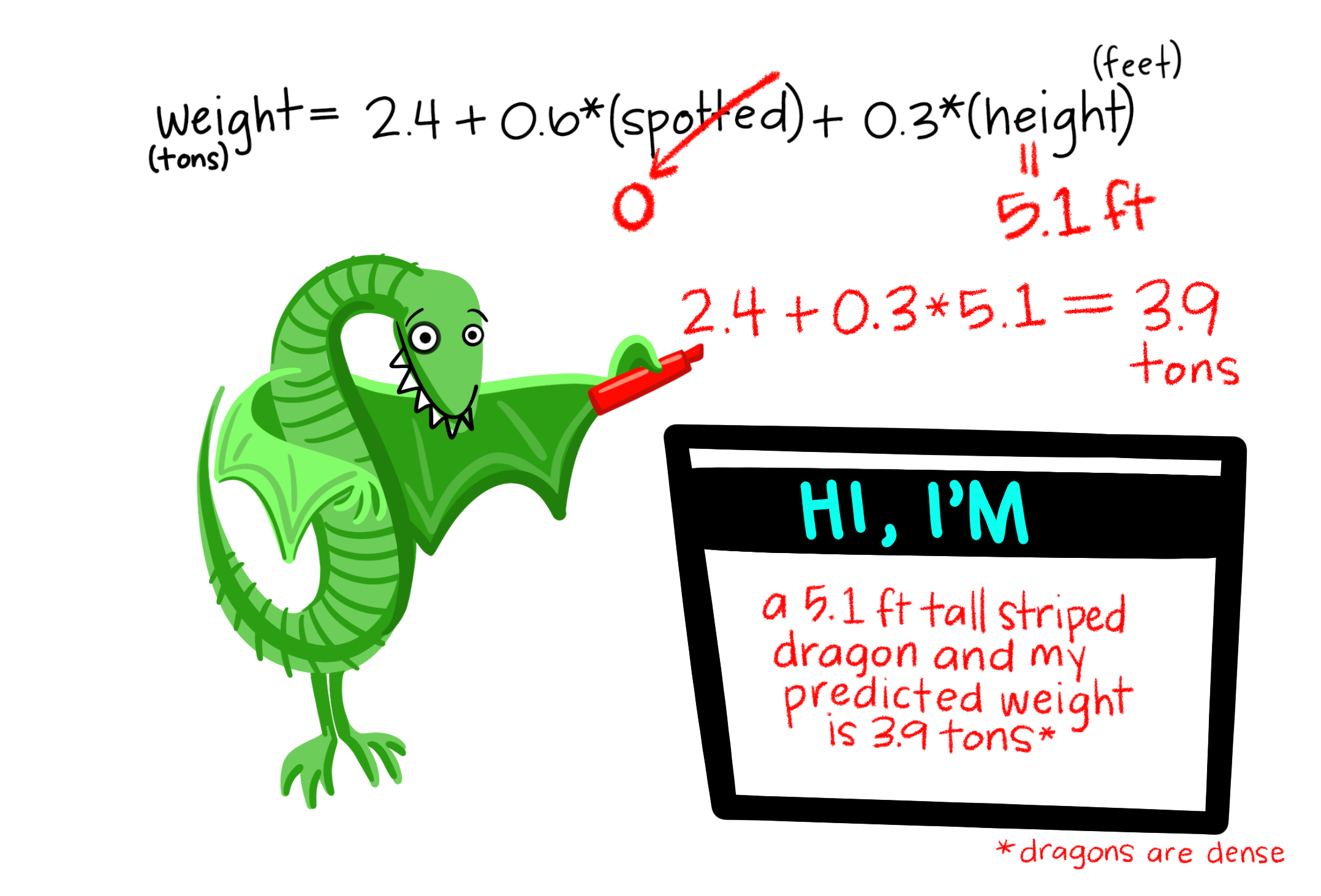
\[ \begin{aligned} \operatorname{bill\_depth\_mm} &= \alpha + \beta_{1}(\operatorname{species_{Chinstrap}}) + \beta_{2}(\operatorname{species_{Gentoo}}) + \epsilon \end{aligned} \]
Fitted model
## first, let's fit the model
fit.lm <- lm(bill_depth_mm ~ species, data = penguins_nafree)
## ok, now let's look at the regression coefficents output table
summary(fit.lm)$coef
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 18.34726027 0.09299608 197.2906740 0.000000e+00
## speciesChinstrap 0.07332796 0.16497460 0.4444803 6.569867e-01
## speciesGentoo -3.35062162 0.13877592 -24.1441135 6.622121e-75Here, the Estimate of the (Intercept) (\(\alpha\) in the model) gives us the estimated average bill depth (mm) of the Adelie penguins. So, in this model, the estimated average bill depth of Adelie penguins is 18.35 mm.
The Estimate of speciesChinstrap (\(\beta_1\) in the model) is the average difference in bill depth of Chinstraps from Adelies. It is a positive value, so here the average bill depth of Chinstrap penguins is estimated to be 0.07 mm larger than the average of Adelie penguins. More generally, the Estimate of \(\beta_1\) in this model tell us the average difference in the response for this group/level, relative to the (Intercept) group/level Estimate.
The Estimate of speciesGentoo (\(\beta_2\) in the model) is the average difference in bill depth of Gentoos from Adelies. It is a negative value, so here the average bill depth of Gentoo penguins is estimated to be 3.35 mm smaller than the average of Adelie penguins. More generally, the Estimate of \(\beta_2\) in this model tell us the average difference in the response for this group/level, relative to the (Intercept) group/level Estimate.
You can visualise these differences in group averages by looking at the plot below, where the dashed horizontal lines represent the group averages for the Adelie (pink), Chinstrap (green) and Gentoo (blue) penguins.
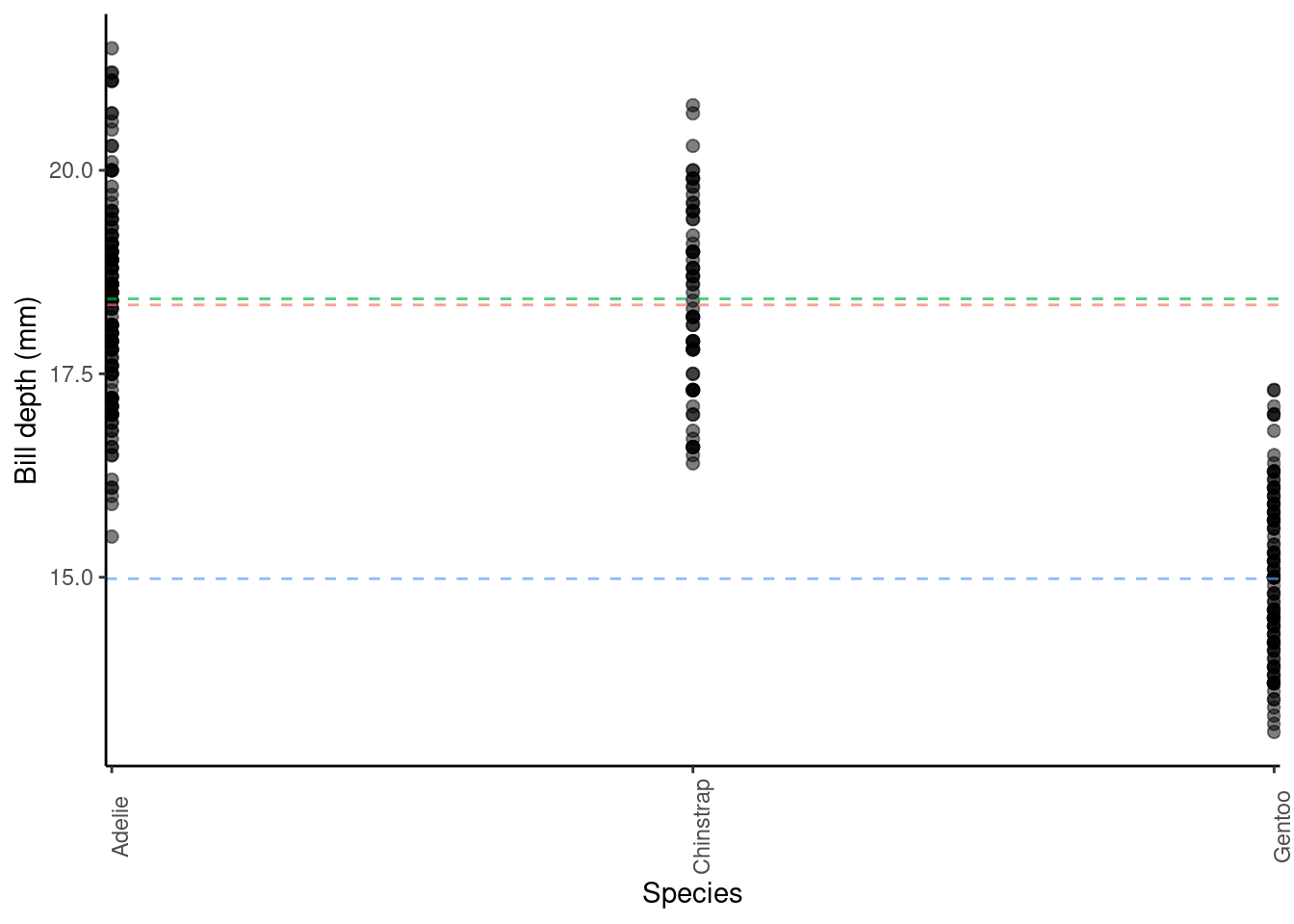
7.1.6 A continuous and a categorical factor explanatory variable (Additive model)
Does adding in bill_length_mm back into the model, along with species help explain more of the variation in bill_depth_mm?
p2 <- ggplot(data = penguins_nafree,
aes(y = bill_depth_mm, x = bill_length_mm, color = species)) +
geom_point() + ylab("Bill depth (mm)") +
xlab("Bill length (mm)") + theme_classic()
p2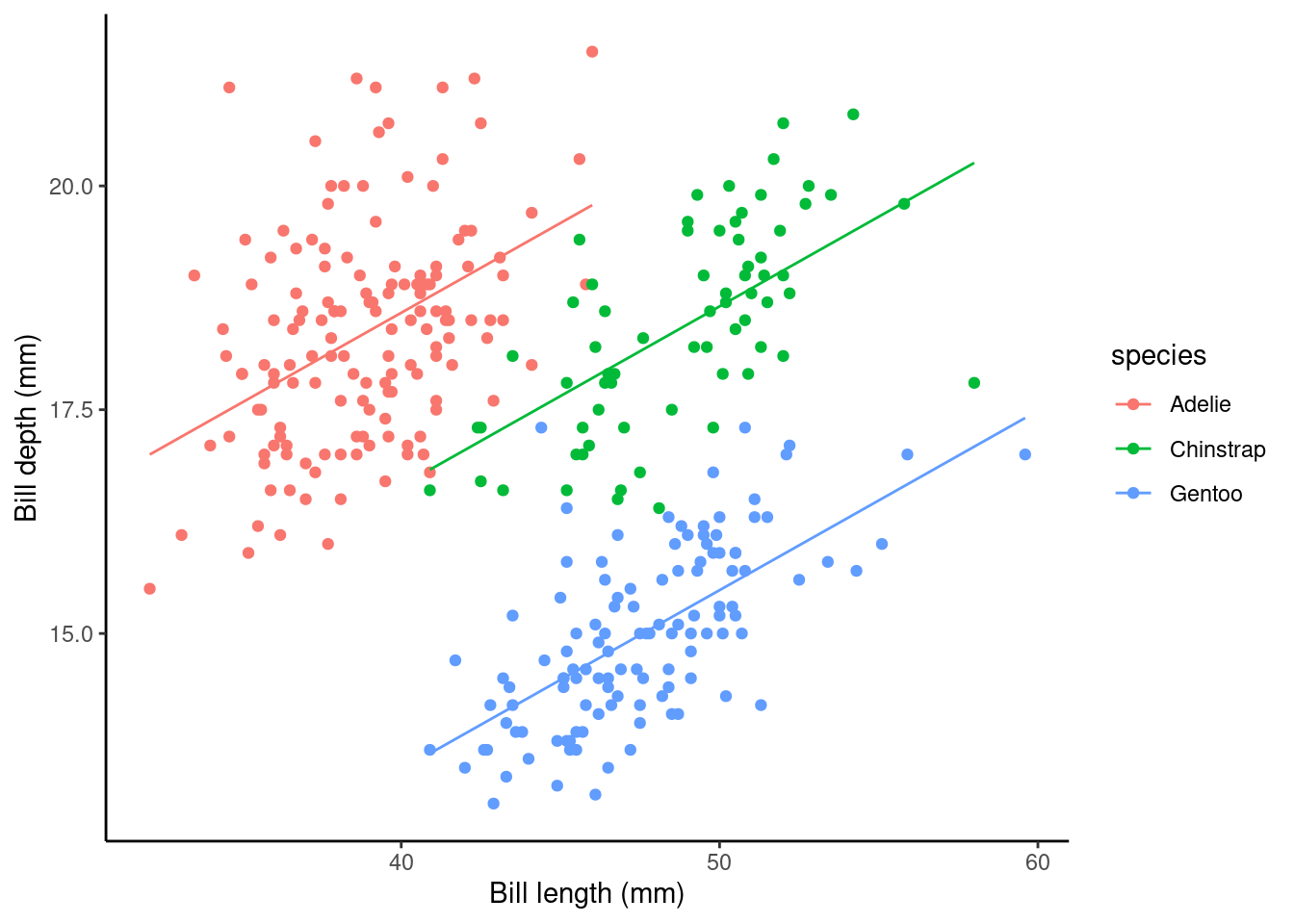
# notice the + between the two explanatory variables?
# this + is what indicates this is an additive model
slm_sp <- lm(bill_depth_mm ~ bill_length_mm + species, data = penguins_nafree)Model formula
Now we have two explanatory variables, if they were both continuous variables, the model formula would be…
\[Y_i = \beta_0 + \beta_1z_i + \beta_2x_i + \epsilon_i\] \[\epsilon_i \sim \text{Normal}(0,\sigma^2)\]
where for observation \(i\)
- \(Y_i\) is the value of the response (
bill_depth_mm) - \(z_i\) is one explanatory variable (
bill_length_mmsay) - \(x_i\) is another explanatory variable (
speciessay) - \(\epsilon_i\) is the error term: the difference between \(Y_i\) and its expected value
- \(\alpha\), \(\beta_1\), and \(\beta_2\) are all parameters to be estimated.
…but because one of the variables is categorical, our model formula needs to be written in the slightly more complicated way we outlined in the previous section
\[Y_i = \beta_0 + \beta_1z_i + \beta_2x_{i,1} + \beta_3x_{i,2} + ... +\beta_kx_{i,k}+ \epsilon_i\]
Another way to write this model formula for this example is
\[ \begin{aligned} \operatorname{bill\_depth\_mm} &= \alpha + \beta_{1}(\operatorname{bill\_length\_mm}) + \beta_{2}(\operatorname{species}_{\operatorname{Chinstrap}}) + \beta_{3}(\operatorname{species}_{\operatorname{Gentoo}})\ + \\ &\quad \epsilon \end{aligned} \]
Fitted model
summary(slm_sp)$coef
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 10.5652616 0.69092642 15.291442 2.977289e-40
## bill_length_mm 0.2004431 0.01767974 11.337449 2.258955e-25
## speciesChinstrap -1.9330779 0.22571878 -8.564099 4.259893e-16
## speciesGentoo -5.1033153 0.19439523 -26.252267 1.043789e-82Here, the Estimate of the (Intercept) (\(\alpha\) or \(\beta_0\) in the model) gives us the estimated average bill depth (mm) of the Adelie penguins given the other variables in the model.
The Estimate of bill_length_mm (\(\beta_1\) in the model) is the slope associated with bill length (mm). So, here for every 1 mm increase in bill length we estimated a 0.2 mm increase in bill depth.
What about the regression coefficients of the other species levels (Estimate for speciesChinstrap and speciesGentoo)? These values give the shift (up or down) of the parallel lines from the Adelie ((Intercept)) level. So given the estimated relationship between bill depth and bill length these coefficients are the estimated change for each species from the baseline. You can visualise this by looking at the plot below.
## calculate predicted values
penguins_nafree$pred_vals <- predict(slm_sp)
## plot
ggplot(data = penguins_nafree, aes(y = bill_depth_mm, x = bill_length_mm, color = species)) +
geom_point() + ylab("Bill depth (mm)") +
xlab("Bill length (mm)") + theme_classic() +
geom_line(aes(y = pred_vals))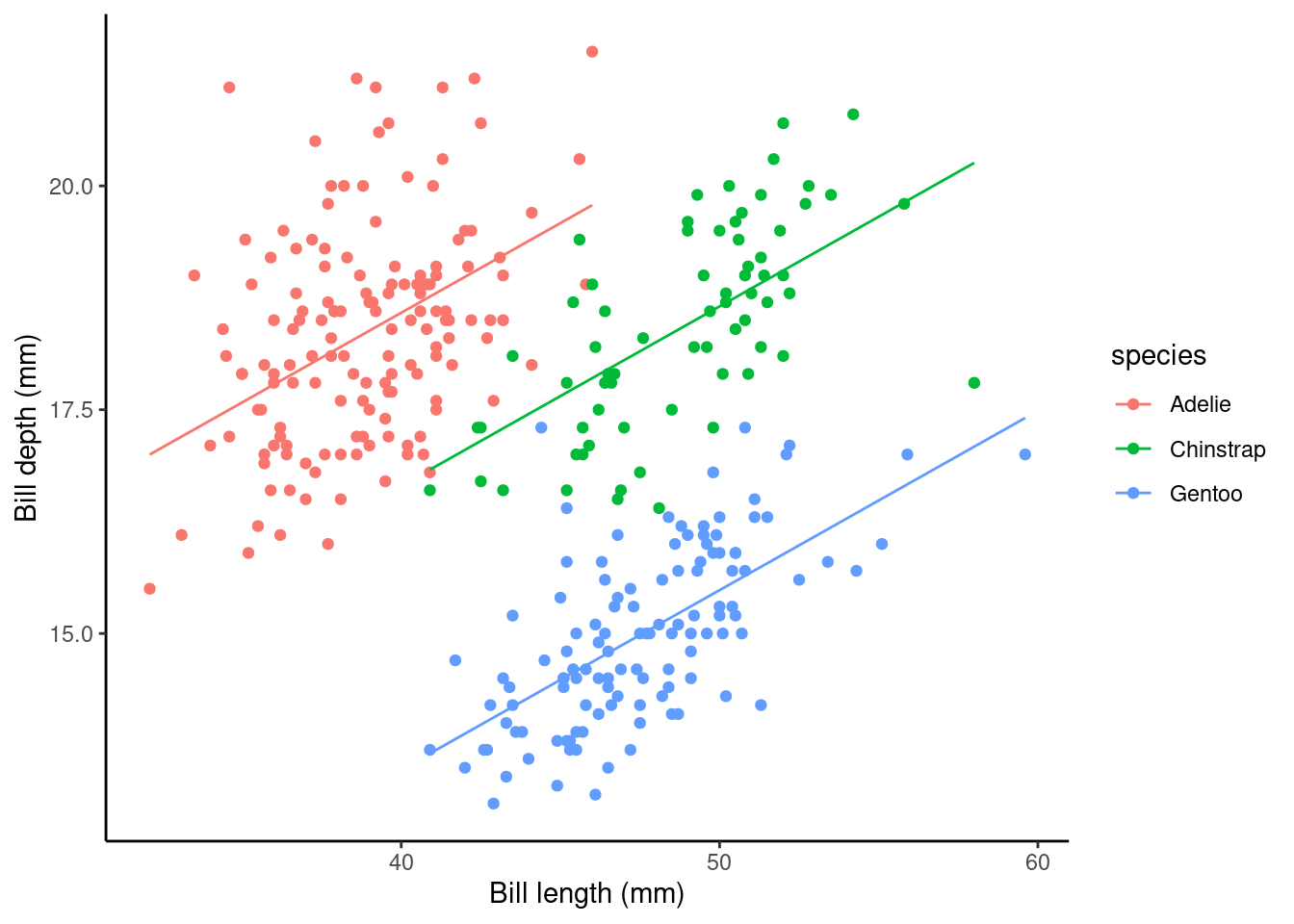
7.1.7 A continuous and a categorical factor explanatory variable (Interaction model)
Recall the additive model formula from above
\[Y_i = \beta_0 + \beta_1z_i + \beta_2x_i + \epsilon_i\] An additive model will always produce regression lines that are parallel with each other (i.e., there is no relationship between the explanatory variables, they act independently of each other)…
…but we should really check to see if the explanatory variables have relationships with each other (i.e., the explanatory variables do not act independently on the response variable.). If this is the case, the regression lines will not be parallel with each other.
Model formula
This is still for two explanatory variables
\[Y_i = \beta_0 + \beta_1z_i + \beta_2x_{i,1} + \beta_3x_{i,2} + ... +\beta_kx_{i,k}+ \beta_4z_ix_{i,k} + \epsilon_i\] You’ll notice a new term \(\beta_4z_ix_{i,k}\) in this model compared to the additive model. This is the interaction term between the two explanatory variables \(z_i\) and \(x_{i,k}\).
The model formula for our penguin example can also be written as
\[ \begin{aligned} \operatorname{bill\_depth\_mm} &= \alpha + \beta_{1}(\operatorname{bill\_length\_mm}) + \beta_{2}(\operatorname{species}_{\operatorname{Chinstrap}}) + \beta_{3}(\operatorname{species}_{\operatorname{Gentoo}})\ + \\ &\quad \beta_{4}(\operatorname{bill\_length\_mm} \times \operatorname{species}_{\operatorname{Chinstrap}}) + \beta_{5}(\operatorname{bill\_length\_mm} \times \operatorname{species}_{\operatorname{Gentoo}}) + \epsilon \end{aligned} \]
where \(\beta_4\)bill_length_mm x speciesChinstrap and \(\beta_5\)bill_length_mm x speciesGentoo represent the interaction terms in the model.
This is getting pretty complicated already and we only have two explanatory variables!!!
However, we can add in more explanatory variables, both categorical and/or continuous, with additive and/or interaction terms between variables and the same principles for inference apply. We will practice with slightly more complicated data in our lab assignment this week.
Note: we can include interaction effects in our lm() model in R by using either the * or : syntax in our model formula. For example,
:denotes the interaction only of the variables to its left and right, and*means to include all main effects and interactions, soa * bis the same asa + b + a:b, whereaandbrepresent the main effects anda:brepresents the interaction term in the model.
To specify a model with additive and interaction effects use either
Or the other way we could write this and get the SAME MODEL is
slm_int <- lm(bill_depth_mm ~ bill_length_mm + species +
bill_length_mm : species, data = penguins_nafree)Fitted model
summary(slm_int)$coef
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 11.48770713 1.15987305 9.9042797 2.135979e-20
## bill_length_mm 0.17668344 0.02980564 5.9278518 7.793199e-09
## speciesChinstrap -3.91856701 2.06730876 -1.8954919 5.890889e-02
## speciesGentoo -6.36675118 1.77989710 -3.5770333 4.000274e-04
## bill_length_mm:speciesChinstrap 0.04552828 0.04594283 0.9909769 3.224296e-01
## bill_length_mm:speciesGentoo 0.03092816 0.04111608 0.7522157 4.524625e-01As before, the Estimate of the (Intercept) gives us the estimated average bill depth (mm) of the Adelie penguins given the other variables in the model.
The bill_length_mm : Estimate (\(\beta_1\) in the model) is the slope associated with bill length (mm). So, here for every 1 mm increase in bill length we estimated a 0.177 mm increase in bill depth.
The main effects of species (i.e., Estimate for speciesChinstrap and speciesGentoo) again give the shift (up or down) of the lines from the Adelie level; however these lines are no longer parallel! The interaction terms (i.e., bill_length_mm:speciesChinstrap and bill_length_mm:speciesGentoo) specify the species specific slopes given the other variables in the model.
## calculate predicted values
penguins_nafree$pred_vals <- predict(slm_int)
## plot
ggplot(data = penguins_nafree, aes(y = bill_depth_mm, x = bill_length_mm, color = species)) +
geom_point() + ylab("Bill depth (mm)") +
xlab("Bill length (mm)") + theme_classic() +
geom_line(aes(y = pred_vals))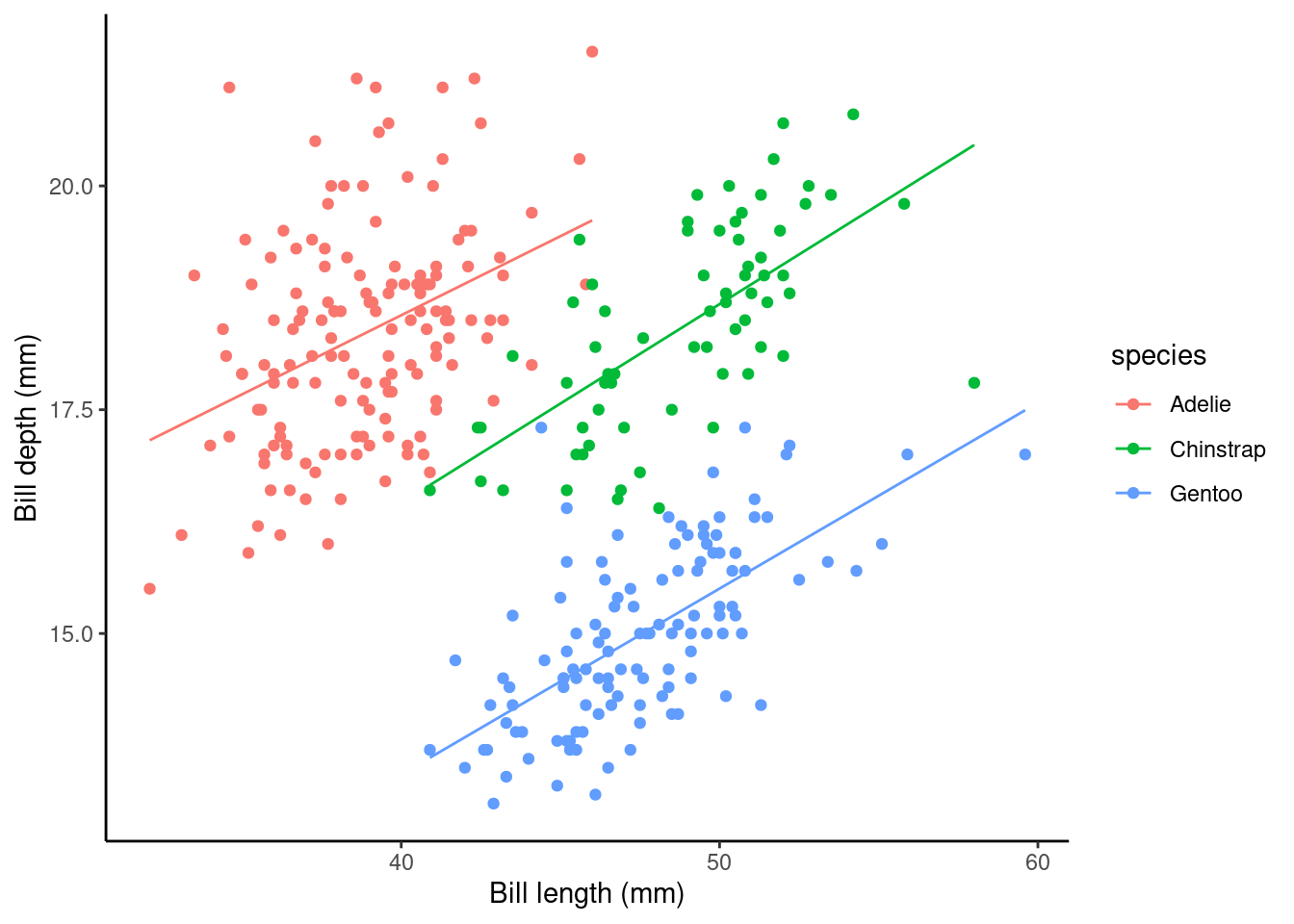
Look at the plot above. Now we’ve specified this all singing and dancing interaction model we might ask are the non-parallel lines non-parallel enough to say this model is better than the parallel line model?
7.2 Model comparison, selection, and checking (again)
Remember that it is always is imperative that we check the underlying assumptions of our model! If our assumptions are not met then basically the maths falls over and we can’t reliably interpret the outputs from the model (e.g., can’t trust the parameter estimates etc.).
Key assumptions of linear regression models
- Independence
- There is a linear relationship between the response and the explanatory variables
- The residuals have constant variance
- The residuals are normally distributed
Let’s look at the fit of the slm model (single continuous explanatory variable)
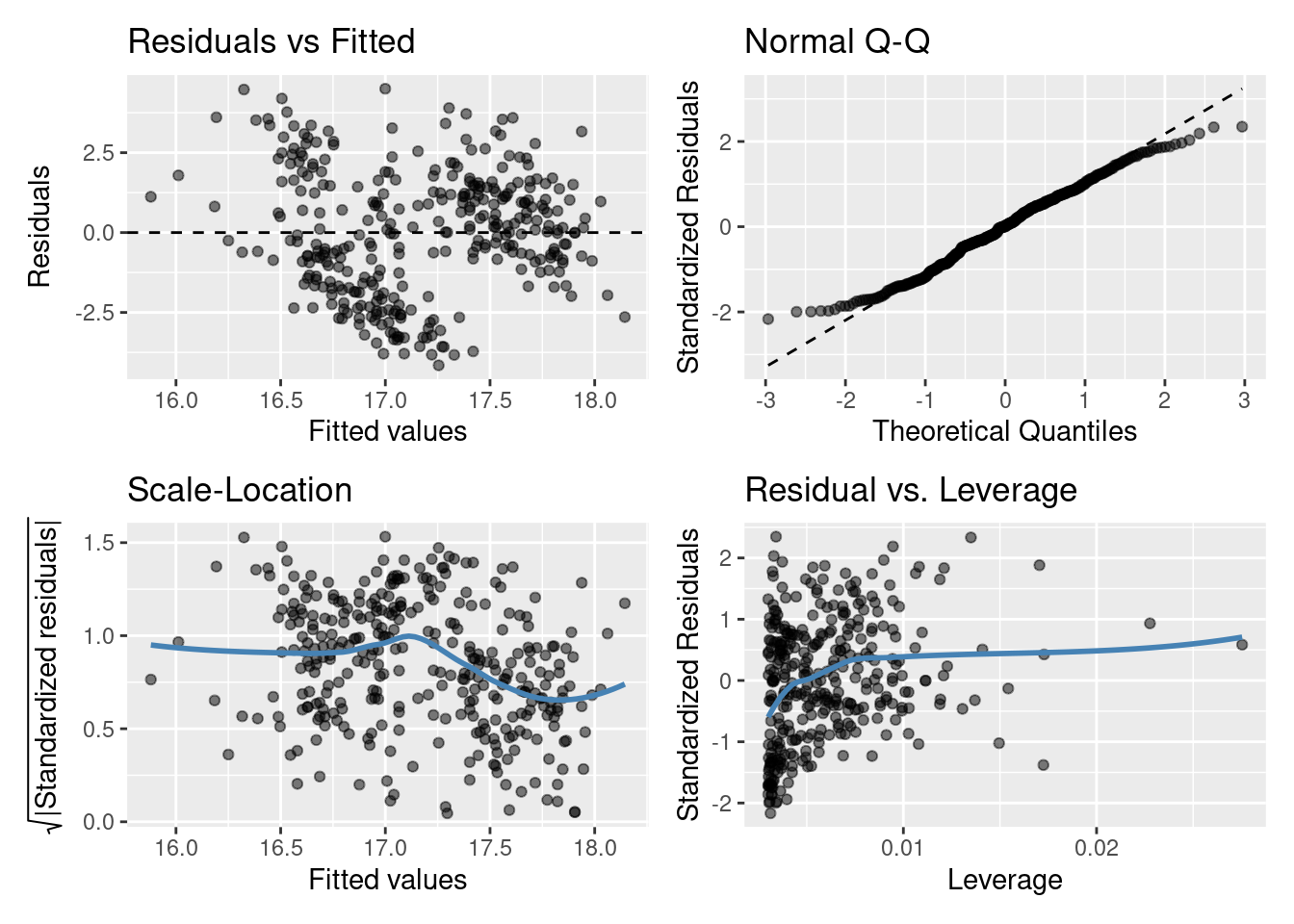
Do you think the model assumptions have been met? Think of what this model is, do you think it’s the best we can do?
7.2.1 Model comparison and selection
A good model not only needs to fit data well, it also needs to be parsimonious. That is, a good model should be only be as complex as necessary to describe a data set. If you are choosing between a very simple model with 1 explanatory variable, and a very complex model with, say, 10 explanatory variables, the very complex model needs to provide a much better fit to the data in order to justify its increased complexity. If it can’t, then the simpler model should be preferred. After all, it’s also much easier to interpret a simpler model (look at our increased complexity from just adding the interaction term in a two explanatory variable model)!
7.2.1.1 Model comparison using anova()
We can compare nested linear models using hypothesis testing. Luckily the R function anova() automates this if you input the two regression objects as separate arguments. Yes, it’s the same idea as we’ve previously learnt about ANOVA. We perform an F-test between the nested models!
By nested we mean that one model is a subset of the other (i.e., where the coefficients both models have in common cancel each other out, so they are essentially weighted at zero). For example,
\[Y_i = \beta_0 + \beta_1z_i + \epsilon_i\]
is a nested version of
\[Y_i = \beta_0 + \beta_1z_i + \beta_2x_i + \epsilon_i\] This ANOVA will test whether or not including \(\beta_2x_i\) leads to a significant improvement in the model.
As an example consider testing the single explanatory variable model slm against the same model with species included as a variable slm_sp. To carry out the appropriate hypothesis test in R we can run
anova(slm,slm_sp)
## Analysis of Variance Table
##
## Model 1: bill_depth_mm ~ bill_length_mm
## Model 2: bill_depth_mm ~ bill_length_mm + species
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 331 1220.16
## 2 329 299.62 2 920.55 505.41 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1As you’ll see the anova() function takes two model objects (slm and slm_sp) each as arguments. It returns an ANOVA testing whether the simpler model (slm) is just as good at capturing the variation in the data as the more complex model (slm_sp). The returned p-value should be interpreted as in any other hypothesis test. i.e., the probability of observing a statistic as least as extreme under our null hypothesis (here, that either model is as good as each other at capturing the variation in the data, or model 1 = model 2, or model 1 - model 2 = 0).
What would we conclude here from the output above comparing slm and slm_sp? We can see the results show a Df of 2 (indicating that the more complex model has two additional parameters) and a very small p-value (<2e-16). I’d say we have very strong evidence against the models being equally good, and adding species to the model lead to a significantly improved fit over slm without species! Looking at the relevant plots, does this make sense?
Now what about slm_int vs slm_sp?
Are the non-parallel lines non-parallel enough to say the more complicated interaction model is better than the simpler parallel line additive model?
anova(slm_sp,slm_int)
## Analysis of Variance Table
##
## Model 1: bill_depth_mm ~ bill_length_mm + species
## Model 2: bill_depth_mm ~ bill_length_mm + species + bill_length_mm:species
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 329 299.62
## 2 327 298.62 2 0.99284 0.5436 0.5812So it seems both models are just as good at capturing the variation in our data: we’re happy with the simpler model with parallel lines!
7.2.1.2 Model comparison using AIC()
Another way we might compare models is by using the Akaike information criterion (AIC) (you’ll see more of this later in the course). AIC is an estimator of out-of-sample prediction error and can be used as a metric to choose between competing models. Lower AIC scores are better, and AIC penalizes models that use more parameters. So if two models explain the same amount of variation, the one with fewer parameters (df) will have a lower AIC value (i.e., smallest out-of-sample prediction error) and will be the better-fit model. Typically, a difference of 4 or more is considered to indicate an improvement; this should not be taken as writ however, using multiple comparison techniques is advised.
R has an AIC() function that can be used directly on your lm() model objects. The AIC() function can take multiple arguments compared to anova() that can only compare two models at a time. For example,
AIC(slm_null, slm, slm_sp, slm_int)
## df AIC
## slm_null 2 1399.3234
## slm 3 1383.4462
## slm_sp 5 919.8347
## slm_int 7 922.7294This supports what the anova() output suggested; slm_sp is the preferred model. As always it’s important to do a sanity check! Does this make sense? Have a look at the outputs from these models and see what you think.
Just because we’ve chosen a model (the best of a bad bunch perhaps?) this doesn’t let us off the hook. We should check our assumptions…
…well, we should have checked them before we started to interpret the data!
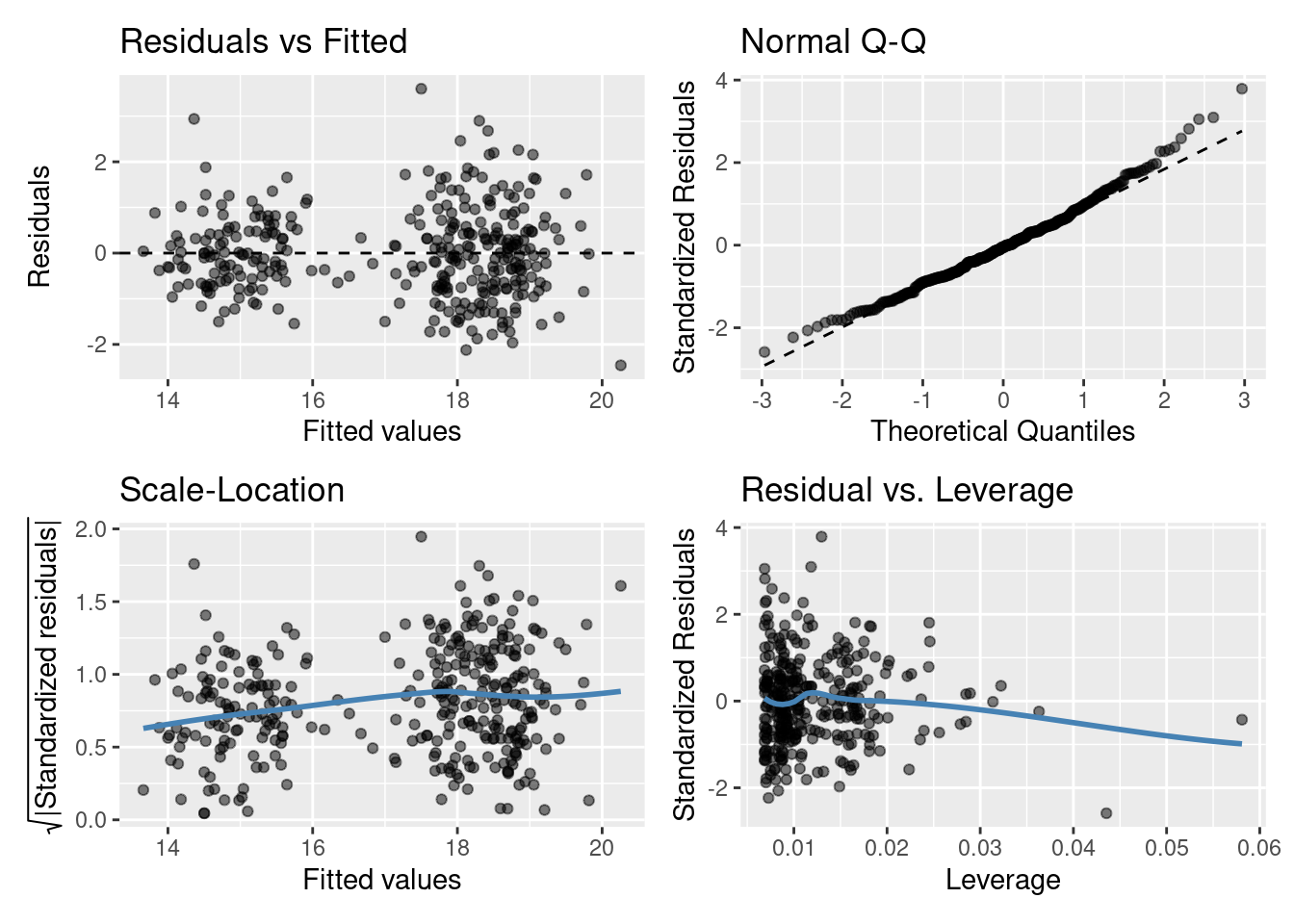
Residuals vs Fitted plot: equal spread? Doesn’t look too trumpety/slice of pizza shaped! Don’t worry that there aren’t many points between 16-17 on the x-axis.
Normal quantile-quantile (QQ) plot: skewed? Maybe slightly right skewed (deviation upwards from the right tail) but probably nothing to worry about.
Scale-Location plot: equal spread and relatively straight line? I’d say so.
Residuals vs Leverage: ? Maybe a couple of points with high leverage.
7.3 Confidence intervals and point predictions
So far, we’ve got population parameter estimates from our linear regression models (all the \(\alpha\)s and \(\beta\)s!). We’ve used other statistical tools to check the linear regression model assumptions are met and also selected the best model (in terms of which explanatory variables are most useful, and whether they should be treated as independent from each other (additive) or interacting). However, there’s a couple more things we might like to do, such as:
- determine confidence intervals for parameter estimates
- make point predictions (i.e., input explanatory variable information to predict the response variable)
7.3.1 Confidence intervals
Confidence intervals provide a range of values around a population estimate that are believed to contain, with a certain probability (e.g., 95%), the true value of that estimate. They provide a way to quantify the uncertainty about the value of that population estimate we have calculated from the sample data.
For the chosen slm_sp model we can get the confidence intervals for the regression coefficient estimates in R by using the confint() function.
cis <- confint(slm_sp)
cis
## 2.5 % 97.5 %
## (Intercept) 9.2060707 11.9244526
## bill_length_mm 0.1656635 0.2352227
## speciesChinstrap -2.3771120 -1.4890438
## speciesGentoo -5.4857298 -4.7209009
# By default the 95% confidence intervals are returned
# you can change this using the `level = ` argumentThis tells us that for every 1 mm increase in bill length we are 95% confident the expected bill depth will increase between 0.166 and 0.235 mm (3 sf).
We are 95% confident that the average bill depth of a Chinstrap penguin is between 1.5 and 2.4 mm shallower than the Adelie penguin.
To interpret these correctly we must understand what they are telling us. That is, 95% of the time, our 95% confidence intervals taken from a random sample will contain the true population parameter we are wanting to estimate.
7.3.2 Point prediction
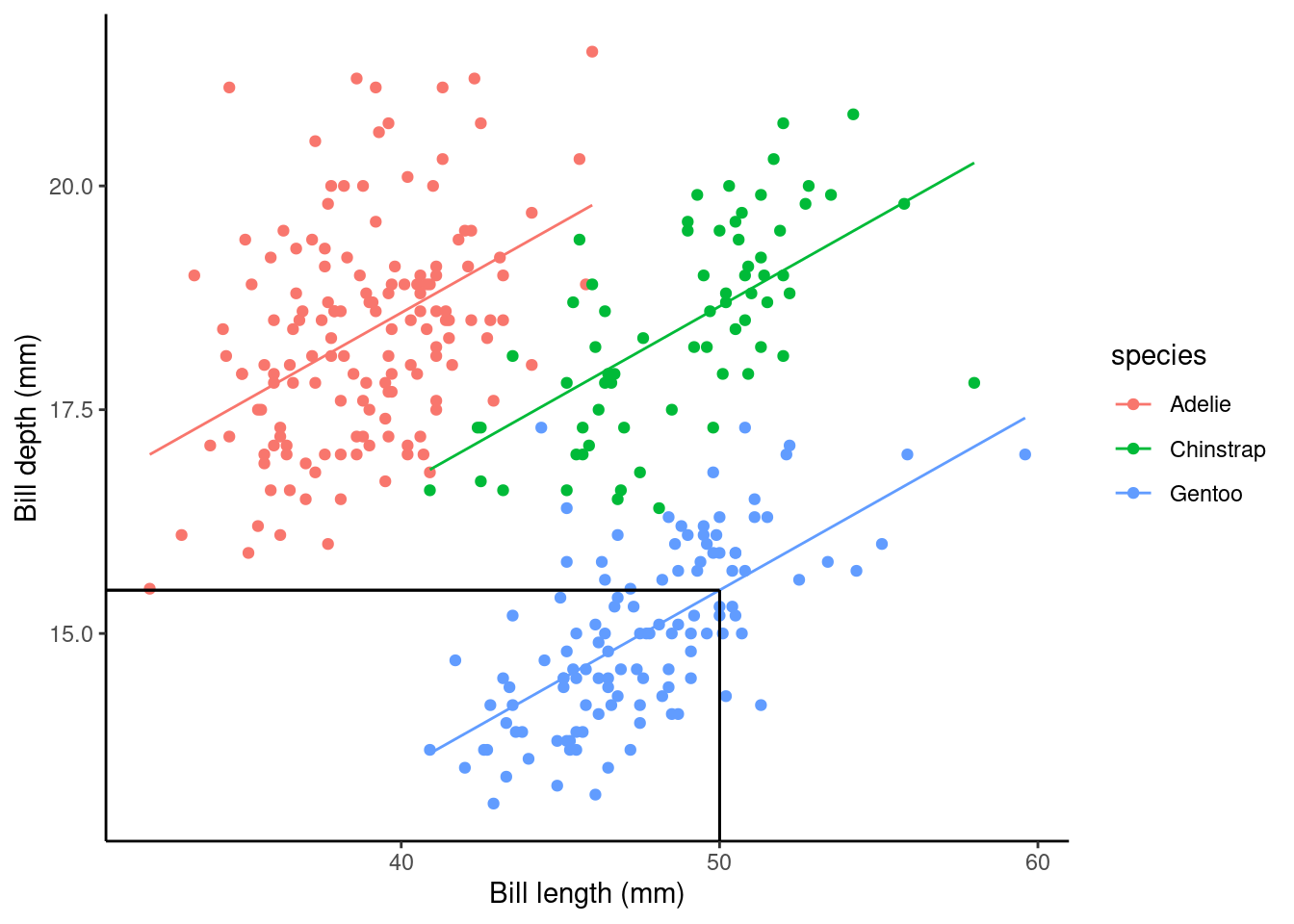
Using the slm_sp model we can make a point prediction for the expected bill depth (mm) for Gentoo penguins with a bill length of 50mm.
Recall the model equation
\[ \begin{aligned} \operatorname{bill\_depth\_mm} &= \alpha + \beta_{1}(\operatorname{bill\_length\_mm}) + \beta_{2}(\operatorname{species}_{\operatorname{Chinstrap}}) + \beta_{3}(\operatorname{species}_{\operatorname{Gentoo}})\ + \\ &\quad \epsilon \end{aligned} \]
And recall the output table from this model, with estimates.
summary(slm_sp)$coef
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 10.5652616 0.69092642 15.291442 2.977289e-40
## bill_length_mm 0.2004431 0.01767974 11.337449 2.258955e-25
## speciesChinstrap -1.9330779 0.22571878 -8.564099 4.259893e-16
## speciesGentoo -5.1033153 0.19439523 -26.252267 1.043789e-82We can then substitute in the values (using our dummy variable coding for species):
\[ \begin{aligned} \widehat{\text{bill depth}} & = \hat{\alpha} + \hat{\beta_1}*50 + \hat{\beta_2}*0 + \hat{\beta_3}*1\\ \ & = 10.56 + 0.20*50 - 1.93*0- 5.10*1\\ \ & = 10.56 + 10 - 5.10\\ \ & = 15.46\text{mm} \end{aligned} \]
Rather than by hand we can do this easily in R
## create new data frame with data we want to predict
## the names have to match those in our original data frame
newdf <- data.frame(species = "Gentoo", bill_length_mm = 50)
## use predict() function
predict(slm_sp, newdata = newdf) ## more accurate than our by hand version!
## 1
## 15.4841What does this look like on a plot?
7.4 TL;DR lm()
| Traditional name | Model formula | R code |
|---|---|---|
| Simple regression | \(Y \sim X_{continuous}\) | lm(Y ~ X) |
| One-way ANOVA | \(Y \sim X_{categorical}\) | lm(Y ~ X) |
| Two-way ANOVA | \(Y \sim X1_{categorical} + X2_{categorical}\) | lm(Y ~ X1 + X2) |
| ANCOVA | \(Y \sim X1_{continuous} + X2_{categorical}\) | lm(Y ~ X1 + X2) |
| Multiple regression | \(Y \sim X1_{continuous} + X2_{continuous}\) | lm(Y ~ X1 + X2) |
| Factorial ANOVA | \(Y \sim X1_{categorical} * X2_{categorical}\) | lm(Y ~ X1 * X2) or lm(Y ~ X1 + X2 + X1:X2) |




7.4.1 Model formula syntax
In R to specify the model you want to fit you typically create a model formula object; this is usually then passed as the first argument to the model fitting function (e.g., lm()).
Some notes on syntax:
Consider the model formula example y ~ x + z + x:z. There is a lot going on here:
- The variable to the left of
~specifies the response, everything to the right specify the explanatory variables +indicates to include the variable to the left and right of it (it does not mean they should be summed):denotes the interaction of the variables to its left and right
Additionally, some other symbols have special meanings in model formula:
*means to include all main effects and interactions, soa * bis the same asa + b + a:b^is used to include main effects and interactions up to a specified level. For example,(a + b + c)^2is equivalent toa + b + c + a:b + a:c + b:c(note(a + b + c)^3would also adda:b:c) (not examinable. Here for your future reference)-excludes terms that might otherwise be included. For example,-1excludes the intercept otherwise included by default, anda*b - bwould producea + a:b(not examinable. Here for your future reference)
Mathematical functions can also be directly used in the model formula to transform a variable directly (e.g., y ~ exp(x) + log(z) + x:z). One thing that may seem counter intuitive is in creating polynomial expressions (e.g., \(x^2\)). Here the expression y ~ x^2 does not relate to squaring the explanatory variable \(x\) (this is to do with the syntax ^ you see above. To include \(x^2\) as a term in our model we have to use the I() (the “as-is” operator). For example, y ~ I(x^2)). (not examinable. Here for your future reference)
7.6 Beyond Linear Models to Generalised Linear Models (GLMs) (not examinable)
Recall the assumptions of a linear model
- The \(i\)th observation’s response, \(Y_i\), comes from a normal distribution
- Its mean, \(\mu_i\), is a linear combination of the explanatory terms
- Its variance, \(\sigma^2\), is the same for all observations
- Each observation’s response is independent of all others
But, what if we want to rid ourselves from a model with normal errors?
The answer: Generalised Linear Models.
7.6.1 Counting animals…
A normal distribution does not adequately describe the response, the number of animals
- It is a continuous distribution, but the response is discrete
- It is symmetric, but the response is unlikely to be so
- It is unbounded, and assumes it is plausible for the response to be negative
In addition, a linear regression model typically assumes constant variance, but in this situation this unlikely to be the case.
So why assume a normal distribution? Let’s use a Poisson distribution instead.
\[\begin{equation*} \mu_i = \beta_0 + \beta_1 x_i, \end{equation*}\]
So \[\begin{equation*} Y_i \sim \text{Normal}(\mu_i\, \sigma^2), \end{equation*}\]
becomes
\[\begin{equation*} Y_i \sim \text{Poisson}(\mu_i), \end{equation*}\]
The Poisson distribution is commonly used as a general-purpose distribution for counts. A key feature of this distribution is \(\text{Var}(Y_i) = \mu_i\), so we expect the variance to increase with the mean.
7.6.2 Other modelling approaches (not examinable)
R function |
Use |
|---|---|
glm() |
Fit a linear model with a specific error structure specified using the family = argument (Poisson, binomial, gamma) |
gam() |
Fit a generalised additive model. The R package mgcv must be loaded |
lme() and nlme() |
Fit linear and non-linear mixed effects models. The R package nlme must be loaded |
lmer() |
Fit linear and generalised linear and non-linear mixed effects models. The package lme4 must be installed and loaded |
gls() |
Fit generalised least squares models. The R package nlme must be loaded |